TL;DR
People are the weakest link your in security chain. We can all be tricked and few of us are cyber-vigilant 100% of the time.
Can we improve security and enhance user satisfaction at the same time?
Passkeys are a revolutionary shift in how we demonstrate “I am who I say I am” (aka. authentication, aka. authn). They are a secure and user-friendly alternative to traditional passwords.
Passkeys provide a robust alternative to traditional passwords.
With over 15 billion passkey-enabled accounts globally, the adoption is rapidly increasing.
Organizations recognize the benefits of both improved security and user experience.
Advantages include:
– Phishing Resistance: Passkeys are bound to specific domains, making them ineffective on fraudulent sites.
– User Experience: Passkeys streamline the login process, resulting in faster authentication and reduced cognitive load for users.
– Unique Credentials: Each service receives a distinct key pair, eliminating the risk of password reuse
– Automatic Strength: Keys exceed the strength of human-created passwords
– Reduced Social Engineering Risks: With no memorable secrets to extract, the potential for somebody to socially engineer your password is significantly diminished
But passkeys face several implementation challenges:
– Device Dependency: A significant portion of enterprises (43%) cite the complexity of implementing passkeys due to device compatibility issues.
– Recovery Risks: Users risk losing access if all authenticated devices are lost, necessitating robust fallback protocols.
– Cross-Platform Gaps: Support for passkeys varies across ecosystems, particularly between Apple, Google, and Microsoft.
– Legacy System Inertia: Many organizations still rely on passwords, with 56% of enterprises continuing to use them even after adopting passkeys.
– Learning Curve: Everybody understands passwords, while passkeys (and the key management) are something new.
This post delves into the benefits of passkeys, their mechanics, the adoption trends, and the challenges they present.
- TL;DR
- The Dichodomy of Security and Usability
- How Do Passkeys Work? The Tech Behind the Magic
- Passkeys are Working: Adoption Trends You Need to Know
- Passkeys vs. Traditional MFA: The Showdown
- The Flip Side: Challenges and Limitations of Passkeys
- Looking Ahead: The Future of Passkeys in Authentication
- In Conclusion: Embracing the Passkey Revolution
The Dichodomy of Security and Usability
Former FBI Director William H. Webster “There is always too much security until it is too little”
Between professional life and personal life, we consistently use compute devices (phones, televisions, tablets, workstations, etc.). It’s near impossible to have your “guard up” every time you’re online.
Passkeys improve user experience:
– Speed: Users experience significantly faster logins with passkeys. For example, Amazon users log in six times faster using passkeys than with traditional methods.
– Success Rate: According to a MSFT study, the success rate for passkey authentication is 98%, while traditional password methods struggle with a mere 32% success rate.
– Cognitive Load: Passkeys eliminate the need for users to manage passwords, reducing the cognitive burden associated with remembering and entering credentials (which explains the higher login success rate).
Dashlane’s findings indicate that passkeys can lead to a 70% increase in conversion rates compared to password-based authentication, demonstrating their potential to enhance user engagement.
Phishing Resistance
We are all vulnerable to a well-crafted phishing attack. Sophisticated attackers use techniques that can fool even the most cyber savvy person while winding-down from a long day.
The cryptographic architecture underpinning passkeys, binds credentials to specific web domains. This architecture prevents phishing attempts, as passkeys can only be used on legitimate sites. Whenever you authenticate, the passkey verifies the website’s authenticity before proceeding. This means that even if a your were somehow tricked into visiting a fraudulent site, the passkeys remain secure and unusable on that domain.
This is a significant improvement over traditional passwords, which can be easily entered on phishing sites that look identical to real sites.
Preventing Poor Cyber Hygeine
Let’s admit it, the fantasy of a centralized and trusted provider that manages your identity across all online services is just that – a fantasy. Your place of work may have single sign on (SSO) and you may be using Google or Microsoft to for many personal sites, but there is always going to be a large number of platforms that aren’t integrated.
This means you need to keep track of authentication credentials for hundreds, if not thousands, of different accounts (all belonging to you!)
Passkeys address common problems with password management:
– Unique Credentials: Each service receives a distinct key pair, eliminating the risk of password reuse – I’m sure you’ve never reused a password
– Automatic Strength: Keys are generated to meet cryptographic standards, far exceeding the strength of human-created passwords – even those sites with nonsensical password complexity requirements
– Reduced Social Engineering Risks: With no memorable secrets to extract, the potential for somebody to socially engineer your password is significantly diminished
How Do Passkeys Work? The Tech Behind the Magic
The security of passkeys is rooted in asymmetric encryption, which involves the following key processes:
1. Key Pair Generation: During registration, a unique public-private key pair is created. The public key is stored on the server, while the private key remains securely on the user’s device.
2. Zero Secret Sharing: Authentication is performed through cryptographic challenges that utilize the private key, eliminating the need to transmit sensitive information. This means that even if a server is compromised, only non-sensitive public keys are at risk.
This cryptographic approach makes brute-force attacks impractical, as private keys are never exposed and typically contain 256 bits of entropy, making them highly resistant to guessing.
Passkeys utilize asymmetric cryptography to enhance security and streamline user workflows, fundamentally changing how authentication is performed.
Registration Ceremony

The registration of a passkey involves a series of steps that leverage the WebAuthn API. Here’s a simplified breakdown of the process:
1. User Initiation: The user selects “Create Passkey,” which triggers the WebAuthn API.
2. Retrieve Challenge: The website (more formally called the “Relying Party”) then provides a challenge. The challenge is a critical nonce value that guarantees the freshness, uniqueness, and cryptographic proof of the registration process.
3. Key Generation: The authenticator (operating system, software key manager, or hardware security key) typically requests user verification. When confirmed the authenticator generates a unique public-private key pair, assigns an ID to the key (for later retrieval), and signs the challenge.
4. **Public Key Storage: The service verifies the challenge and stores the public key along with key ID (this information is used during authentication).
Authentication Flow
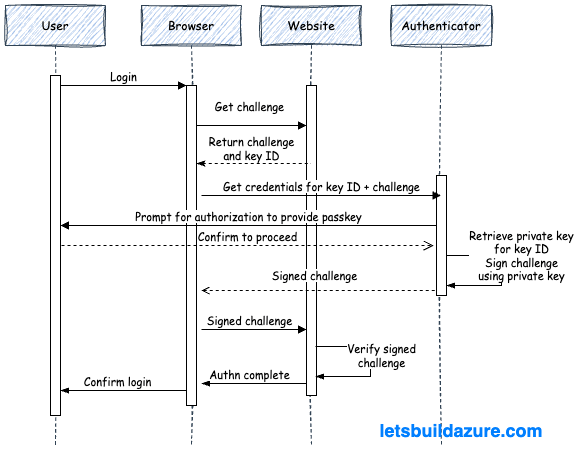
The authentication process is similar to the registration ceremony, but uses information previously stored during registration:
1. User Initiation: The user provides their username and triggers the authentication process.
2. Service Challenge: The server returns a challenge (a cryptographic nonce) and key ID to the user’s device.
2. Local Verification: The authenticator prompts the user for verification (biometric, PIN, etc.).
3. Digital Signature: The authenticator then uses the stored private key (the one associated with the key ID) and signs the challenge, creating a unique signature.
4. Server Validation: This signature is relayed to the server and the server uses the stored public key to verify the authenticity of the signature.
This process is efficient, with reports indicating that passkey logins can be up to 70% faster than traditional password logins, significantly enhancing user experience.
Passkeys are Working: Adoption Trends You Need to Know
The rapid growth of passkey adoption is reshaping both consumer and enterprise authentication landscapes.
Recent metrics indicate that over 15 billion passkey-enabled accounts exist globally, with significant uptake across major platforms. For instance, Google reports 800 million accounts utilizing passkeys, while Amazon has seen 175 million users adopt this technology within its first year of implementation.
In the consumer sector, e-commerce leads the charge, with 42% of passkey usage attributed to improved checkout conversion rates. Air New Zealand experienced a 50% reduction in login abandonment after integrating passkeys, highlighting their effectiveness in enhancing user experience. Furthermore, Intuit has reported that 85% of its mobile authentications now occur via passkeys, underscoring a shift towards more secure and user-friendly authentication methods.
A notable implementation of passkeys can be seen with CVS Health, which reported a 98% reduction in mobile account takeovers after adopting passkey technology. This dramatic decrease highlights the effectiveness of passkeys in mitigating security risks associated with traditional password systems.
Enterprise Adoption Trends
The enterprise sector is also witnessing a significant shift, with 87% of organizations now deploying passkeys. Key areas of focus include:
– Sensitive data access: 39% of enterprises prioritize securing sensitive information.
– Admin accounts: Another 39% emphasize protecting administrative access.
– Executive protection: 34% of organizations are focused on safeguarding executive accounts.
Post-implementation statistics reveal substantial benefits:
– Lower Help Desk Costs: Organizations that adopt passkeys report a 77% reduction in help desk calls related to password issues. This not only saves costs but also enhances productivity by allowing IT teams to focus on more strategic initiatives.
– Long-Term Security Posture: As organizations increasingly adopt passkeys, they will benefit from a more secure authentication framework that is resilient against evolving cyber threats. This positions passkeys as a foundational element of future digital security strategies.
– Hybrid Deployment: Notably, 82% of enterprises are adopting hybrid deployments that combine device-bound and synced passkeys, reflecting a trend towards flexible security solutions.
Passkeys vs. Traditional MFA: The Showdown
Passkeys offer superior security and user experience compared to traditional multi-factor authentication (MFA).
Defining Traditional MFA
Before diving into a comparison of the of passkeys and MFA, let’s understand how MFA has been traditionally implemented.
As the name implies, multi-factor authentication (MFA), involves authenticating with more than one factor…at least two factors (2FA):
– Something you know: This is your password or PIN
– Something you have: This is a physical device (like a smartphone or hardware token) and is the most popular second factor
– Something you are: These are biometrics (finger prints, facial recognition, voice recognition) – this is a touchy subject for data privacy advocates so tred cautiously and make sure you understand where these biometrics are being stored and processed.
Simplifying Authn with Passkeys
The net result of traditional MFA is a multi-step experience to authenticate. This can really annoy power-users trying to move fast and overwhelm the less technically capable. On the other hand, passkeys incorporate multiple factors (something you have and something your are) in a single transaction.
Improved Security Posture
MFA is not impervious to attacks. Recent years have seen several notable examples of MFA compromises, often exploiting human factors, technical weaknesses, or social engineering tactics.
– Cisco (2022): The Yanluowang ransomware group used MFA fatigue and voice phishing (vishing) to trick a Cisco employee into approving MFA requests. This allowed attackers to access Cisco’s corporate VPN and internal systems, leading to data theft and a ransomware threat. Reference
– Uber (2022): Attackers stole an Uber contractor’s credentials via malware on the contractor’s personal device, likely sold on the dark web. They then launched an MFA fatigue attack, repeatedly sending MFA approval requests until the contractor accepted one, granting access to multiple employee accounts. Reference
– Microsoft (2021-2022): The hacker group Lapsus$ used MFA fatigue attacks and social engineering to breach Microsoft’s internal systems, gaining access to employee and high-privilege accounts, including source code repositories for projects like Bing and Cortana. Reference
– **MGM Resorts (2023):** Attackers used social engineering to bypass MFA by calling the service desk and convincing agents to reset passwords without proper verification, enabling ransomware deployment. Reference
– SEC Twitter Accounts (2023): Attackers used SIM swapping to hijack phone numbers associated with accounts lacking MFA protection, then reset passwords to take control of official Twitter accounts. Reference
How do they do this? There are several popular techniques:
– MFA Fatigue (MFA Bombing): Attackers flood users with repeated MFA approval requests, hoping to wear them down until they approve one. This tactic was used against Cisco, Uber, and Microsoft employees.
– Service Desk Social Engineering: Attackers impersonate users calling help desks to reset passwords or enroll new MFA devices, bypassing MFA protections.
– Adversary-in-the-Middle (AITM) Attacks: Phishing pages mimic legitimate login and MFA prompts, capturing credentials and MFA codes in real time to access accounts.
– Session Hijacking: Attackers steal session tokens or cookies after MFA authentication to maintain access without repeated MFA challenges.
– SIM Swapping: Criminals hijack phone numbers to intercept MFA codes sent via SMS or calls, as seen in attacks on SEC Twitter accounts.
– Malware and Endpoint Compromise: Malware on user devices can steal credentials or session tokens, enabling attackers to bypass MFA.
**To be clear, I am not saying MFA should be dropped, but I am saying passkeys provide a more robust alternative**
The Flip Side: Challenges and Limitations of Passkeys
Implementing passkeys introduces significant challenges, particularly concerning device dependency and recovery risks. While passkeys enhance security and user experience, they also create new vulnerabilities that organizations must address.
Device dependency is a primary concern. Passkeys are tied to specific devices, meaning that if a user loses their device or it becomes inoperable, they may lose access to their accounts. According to a report by FIDO, 43% of enterprises cite implementation complexity due to this device dependency, which complicates user access and recovery processes. Users must ensure they have backup devices or recovery methods in place, which can be cumbersome and may lead to frustration.
Recovery risks are another critical issue. If all devices associated with a passkey are lost, users face the daunting task of account recovery. Unlike traditional passwords, which can often be reset through email or SMS verification, passkeys require a more complex recovery process. This can involve fallback protocols that may not be straightforward or user-friendly. For instance, if a user loses their primary device and does not have a secondary device set up for recovery, they may be locked out of their accounts entirely.
Additionally, cross-platform compatibility poses challenges. While major platforms like Apple, Google, and Microsoft support passkeys, the implementation can vary significantly across different ecosystems. This inconsistency can lead to user confusion and hinder widespread adoption. Organizations must navigate these discrepancies to ensure a seamless user experience, which can be resource-intensive.
Moreover, legacy systems present another barrier. Many enterprises still rely on traditional password systems, with 56% of organizations reporting continued password usage even after transitioning to passkeys. This inertia can slow down the adoption of passkeys and complicate the integration of new authentication methods.
Looking Ahead: The Future of Passkeys in Authentication
Passkeys are set to redefine digital security by addressing vulnerabilities inherent in traditional password systems. As organizations increasingly adopt passkeys, innovations are emerging that promise to enhance security and user experience further.
The current landscape shows a significant shift towards passkey adoption, with 92.7% of devices now passkey-ready and enterprise deployments increasing by 14 percentage points since 2022. This growth is driven by the need for stronger security measures against phishing and credential theft, which account for 72% of breaches. The FIDO2 standard, which underpins passkey technology, is becoming the industry norm, pushing organizations to transition from legacy password systems.
Upcoming Innovations in Passkey Technology
1. **Decentralized Recovery Solutions**: Future innovations may include blockchain-based key escrow systems that allow users to recover their passkeys without relying on centralized services. This could mitigate risks associated with losing access to authenticated devices.
2. **IoT Integration**: The FIDO Device Onboard specification aims to extend passkey functionality to Internet of Things (IoT) devices. This will enhance security across a broader range of devices, ensuring that smart home technologies and other connected devices can leverage the same robust authentication methods.
3. **Quantum Resistance**: As quantum computing advances, the need for post-quantum cryptographic algorithms becomes critical. Future passkey implementations may incorporate these algorithms to safeguard against potential quantum attacks, ensuring long-term security.
4. **Enhanced User Experience**: Innovations will likely focus on streamlining the user experience further. For instance, integrating biometric authentication seamlessly into everyday devices can reduce friction while maintaining high security.
5. **Cross-Platform Compatibility**: As passkeys gain traction, efforts to standardize their implementation across different platforms (Apple, Google, Microsoft) will be crucial. This will facilitate smoother transitions for users and organizations adopting passkey technology.
In Conclusion: Embracing the Passkey Revolution
The transition to passkeys marks a pivotal moment in digital security, offering a robust alternative to traditional passwords. Passkeys leverage public key cryptography, providing enhanced phishing resistance and a streamlined user experience. With over 15 billion passkey-enabled accounts globally, organizations are witnessing significant improvements in security metrics and user satisfaction.
| Factor | Passkeys | Traditional Passwords |
|---|---|---|
| Phishing resistance | ✅ Native, origin-bound | ❌ Vulnerable to phishing |
| Sign-in success rate | 98% | 32% |
| User experience | Faster logins, reduced cognitive load | Slower, requires password management |
As the adoption of passkeys continues to grow, organizations should prioritize their implementation to enhance security and improve user engagement. Embracing this technology is not just a trend; it is a necessary step towards a more secure digital future.
As the adoption of passkeys continues to surge, challenges remain, including device dependency and recovery risks. However, the trajectory indicates a strong shift towards passkeys as the standard for secure digital identity. With ongoing innovations and increasing regulatory pressures, the future of authentication is likely to be dominated by passkeys, offering both enhanced security and improved user experiences.